


Linker Scripts and Memory Layout in Embedded C: A Practical Guide
July 02, 2026
2 min
Atomic operations are the foundation of lock-free programming in embedded systems. While mutexes and semaphores provide simple mutual exclusion, they carry overhead: context switches, priority inversion risk, and memory footprint. For high-frequency interrupt-to-task communication or multi-core synchronization, atomic operations offer deterministic, wait-free alternatives — provided you understand the memory model and hardware primitives.
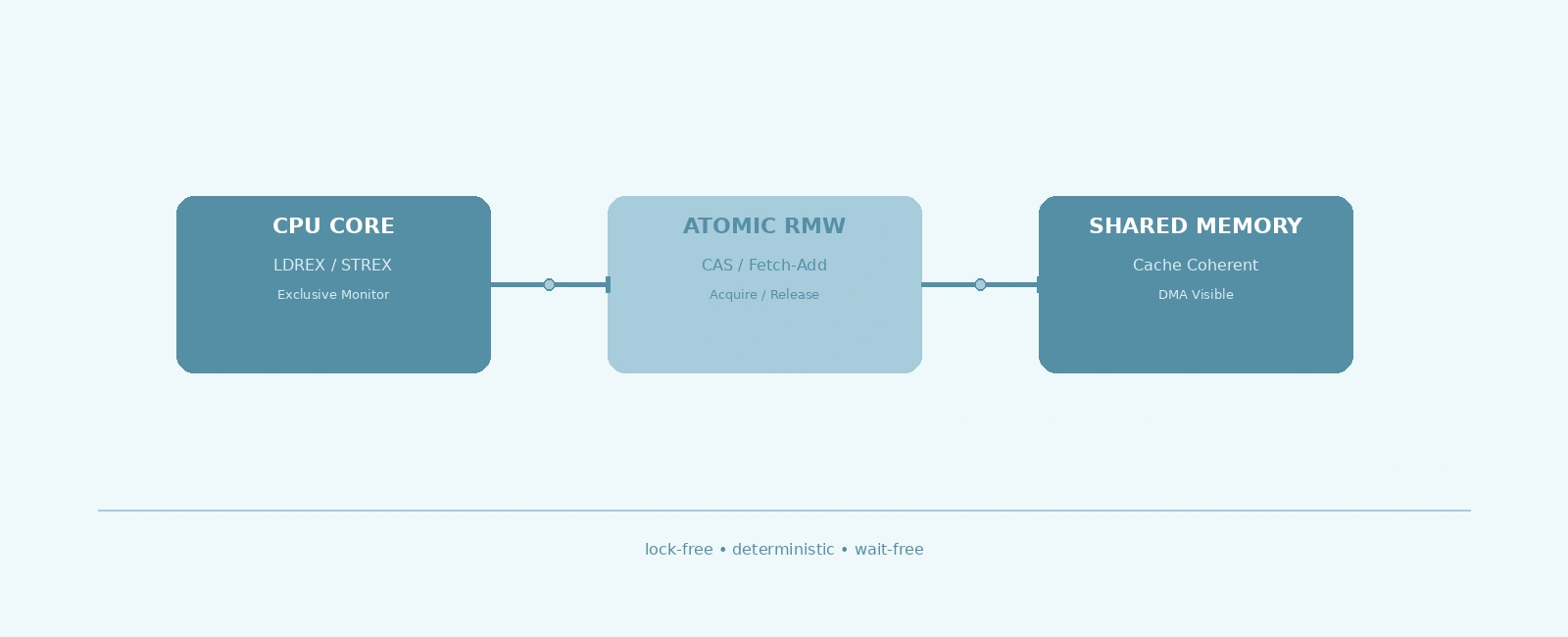
ARM Cortex-M processors (M3/M4/M7/M33) implement the ARMv7-M/ARMv8-M architecture with exclusive access instructions:
+------------------------------------------------------------------+| Cortex-M Exclusive Access Instructions |+------------------------------------------------------------------+| || LDREX Rd, [Rn] Load Register Exclusive (8/16/32-bit) || STREX Rd, Rt, [Rn] Store Register Exclusive (8/16/32-bit) || CLREX Clear Exclusive Monitor || || LDREX/STREX work as a pair: LDREX tags the address, STREX || succeeds only if no other context modified the address since || the LDREX. Returns 0 on success, 1 on failure (retry loop). |+------------------------------------------------------------------+
These instructions form the hardware basis for compare-and-swap (CAS), atomic increment, and other read-modify-write operations. The exclusive monitor is per-core and tracks a single address granule (typically 4-16 bytes).
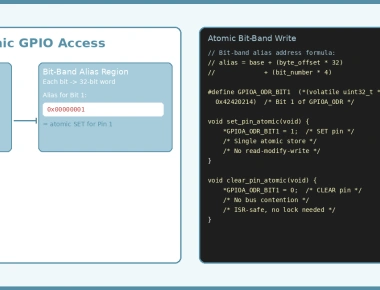
On Cortex-M, aligned 32-bit loads and stores are naturally atomic — they cannot be interrupted mid-transfer. This means:
volatile uint32_t shared_flag = 0;// Thread Ashared_flag = 1; // Atomic store (single STR instruction)// Thread Bif (shared_flag == 1) // Atomic load (single LDR instruction)
However, read-modify-write sequences are NOT atomic:
shared_counter++; // NOT atomic! Compiles to LDR, ADD, STR// Interrupt between LDR and STR loses updates
For RMW operations, you need LDREX/STREX or C11 atomics.
The C11 _Atomic type qualifier and <stdatomic.h> provide portable atomic operations. Modern embedded toolchains (GCC 10+, Clang 12+, IAR 9+) support them for Cortex-M.
#include <stdatomic.h>#include <stdbool.h>#include <stdint.h>// Atomic flag - lock-free on Cortex-Matomic_flag lock = ATOMIC_FLAG_INIT;// Spinlock using test-and-set// WARNING: Avoid spinlocks on single-core systems without disabling interrupts,// as a high-priority thread will spin forever if the lock holder is preempted.void lock_acquire(atomic_flag *lock) {while (atomic_flag_test_and_set_explicit(lock, memory_order_acquire)) {// Spin - in embedded, consider __WFE() for low-power wait__WFE();}}void lock_release(atomic_flag *lock) {atomic_flag_clear_explicit(lock, memory_order_release);__SEV(); // Wake waiting cores}
atomic_int counter = 0;atomic_uintptr_t shared_ptr = 0;// Atomic increment (fetch_add returns old value)int old = atomic_fetch_add_explicit(&counter, 1, memory_order_relaxed);// Compare-and-swap (CAS) - returns true on successuintptr_t expected = old_ptr;bool success = atomic_compare_exchange_strong_explicit(&shared_ptr, &expected, new_ptr,memory_order_acq_rel, memory_order_relaxed);
Critical: Always check ATOMIC_INT_LOCK_FREE macro. On Cortex-M, 32-bit atomics are lock-free (value 2). 64-bit atomics may use library locks (value 1) — avoid them in ISRs.
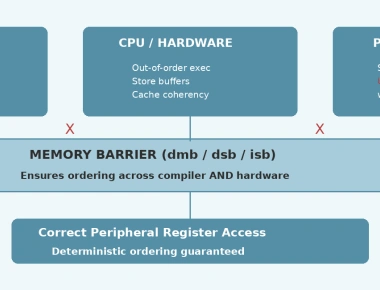
The hardest part of atomics is memory ordering. While Cortex-M enforces strict access ordering for Device and Strongly-ordered memory (e.g., peripherals), Normal memory (SRAM) is weakly ordered, allowing compiler and hardware reordering.
+------------------------------------------------------------------+| C11 Memory Order Quick Reference |+------------------------------------------------------------------+| || memory_order_relaxed No ordering, atomicity only || memory_order_consume Load ordering (deprecated, avoid) || memory_order_acquire Load: subsequent ops don't move before || memory_order_release Store: prior ops don't move after || memory_order_acq_rel RMW: acquire + release || memory_order_seq_cst Full barrier, global total order || || ARM mapping (typical 32-bit): || acquire load -> LDR + DMB || release store -> DMB + STR || RMW operation -> LDREX + ... + STREX |+------------------------------------------------------------------+
#define RB_SIZE 256typedef struct {// Note: Align elements to cache line size (e.g. 32 bytes on Cortex-M7)// to prevent cache line thrashing (false sharing) between cores._Alignas(32) atomic_uint head; // Producer index_Alignas(32) atomic_uint tail; // Consumer index_Alignas(32) uint8_t buf[RB_SIZE];} ringbuf_t;_Static_assert((RB_SIZE & (RB_SIZE - 1)) == 0, "RB_SIZE must be a power of 2");bool rb_push(ringbuf_t *rb, uint8_t data) {uint32_t head = atomic_load_explicit(&rb->head, memory_order_relaxed);uint32_t next = (head + 1) & (RB_SIZE - 1); // Fast modulo for power-of-2// Check full - need acquire to see consumer's tail updateif (next == atomic_load_explicit(&rb->tail, memory_order_acquire))return false; // Fullrb->buf[head] = data;// Release: ensure data write visible before head updateatomic_store_explicit(&rb->head, next, memory_order_release);return true;}bool rb_pop(ringbuf_t *rb, uint8_t *data) {uint32_t tail = atomic_load_explicit(&rb->tail, memory_order_relaxed);// Check empty - need acquire to see producer's head updateif (tail == atomic_load_explicit(&rb->head, memory_order_acquire))return false; // Empty*data = rb->buf[tail];uint32_t next = (tail + 1) & (RB_SIZE - 1); // Fast modulo for power-of-2// Release: ensure data read complete before tail updateatomic_store_explicit(&rb->tail, next, memory_order_release);return true;}
This single-producer, single-consumer (SPSC) ring buffer is wait-free — each operation completes in bounded steps without loops. The acquire/release ordering pairs ensure the producer’s data write is visible to the consumer before the index updates.
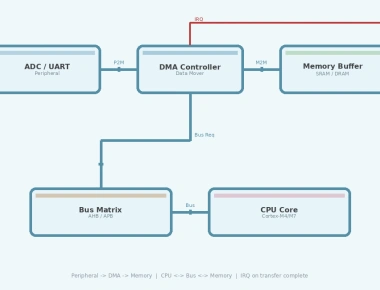
Atomics synchronize between CPU threads/cores. For CPU↔DMA or CPU↔peripheral sharing, you need hardware memory barriers:
// DMA buffer descriptor shared with peripheraltypedef struct {volatile uint32_t src_addr;volatile uint32_t dst_addr;volatile uint32_t length;volatile uint32_t control;// Pad to 32-byte cache line size to prevent cache corruption// of adjacent variables during cache invalidation.uint32_t reserved[4];} dma_desc_t;dma_desc_t desc __attribute__((aligned(32))); // Cache line aligned and paddedvoid start_dma_transfer(uint32_t src, uint32_t dst, uint32_t len) {desc.src_addr = src;desc.dst_addr = dst;desc.length = len;// Note: On Cortex-M7 with D-Cache, clean the cache before DMB// SCB_CleanDCache_by_Addr((uint32_t*)&desc, sizeof(dma_desc_t));// DMB: Ensure all writes to desc complete before// the control write that triggers DMA__DMB();desc.control = DMA_CTRL_ENABLE | DMA_CTRL_IRQ_EN;// DSB: Ensure control write completes before return__DSB();}
Key difference: __DMB() (Data Memory Barrier) orders memory accesses. __DSB() (Data Synchronization Barrier) waits for completion. For DMA, you typically need both.
volatile int counter; // Prevents compiler optimization, NOT atomic!counter++; // Still compiles to LDR/ADD/STR — race condition!
// WRONG: relaxed store, relaxed load - no ordering guaranteeatomic_store_explicit(&ready, 1, memory_order_relaxed);// ... other writes ...// Consumer sees ready=1 but other writes not visible!// CORRECT: release store, acquire loadatomic_store_explicit(&ready, 1, memory_order_release);// Consumer:if (atomic_load_explicit(&ready, memory_order_acquire)) {// All prior writes now visible}
// CAS loop vulnerable to ABA: value changes A->B->A, CAS succeeds incorrectly// Solution: Use tagged pointers or double-width CAS (not on Cortex-M)// Or accept ABA if logically harmless (e.g., reference counting)
Memory barriers (__DMB()) ensure ordering, but they do not flush the data cache. If D-Cache is enabled, DMA might read stale data. Always use SCB_CleanDCache_by_Addr() / SCB_InvalidateDCache_by_Addr() or configure shared RAM as non-cacheable via the MPU.
| Scenario | Recommended Primitive |
|---|---|
| Simple counter/flag shared ISR↔Task | Atomic (lock-free) |
| Single pointer handoff | Atomic with acquire/release |
| SPSC ring buffer | Atomic indices |
| Complex multi-variable invariant | Mutex |
| Need to block/wait with timeout | Semaphore/Mutex |
| Multi-producer/multi-consumer | Mutex or lock-free queue (complex) |
Atomic operations on Cortex-M map directly to LDREX/STREX hardware primitives, providing wait-free synchronization for simple shared data. The C11 <stdatomic.h> interface gives portable access with explicit memory ordering. Master the acquire/release pairing — it’s the key to correct lock-free code. For DMA and peripheral sharing, supplement with __DMB()/__DSB() barriers. Choose atomics for high-frequency, low-contention synchronization; reach for mutexes when invariants span multiple variables or you need blocking semantics.
Quick Links
Legal Stuff