




Volatile vs Memory Barriers — When Volatile Isn't Enough
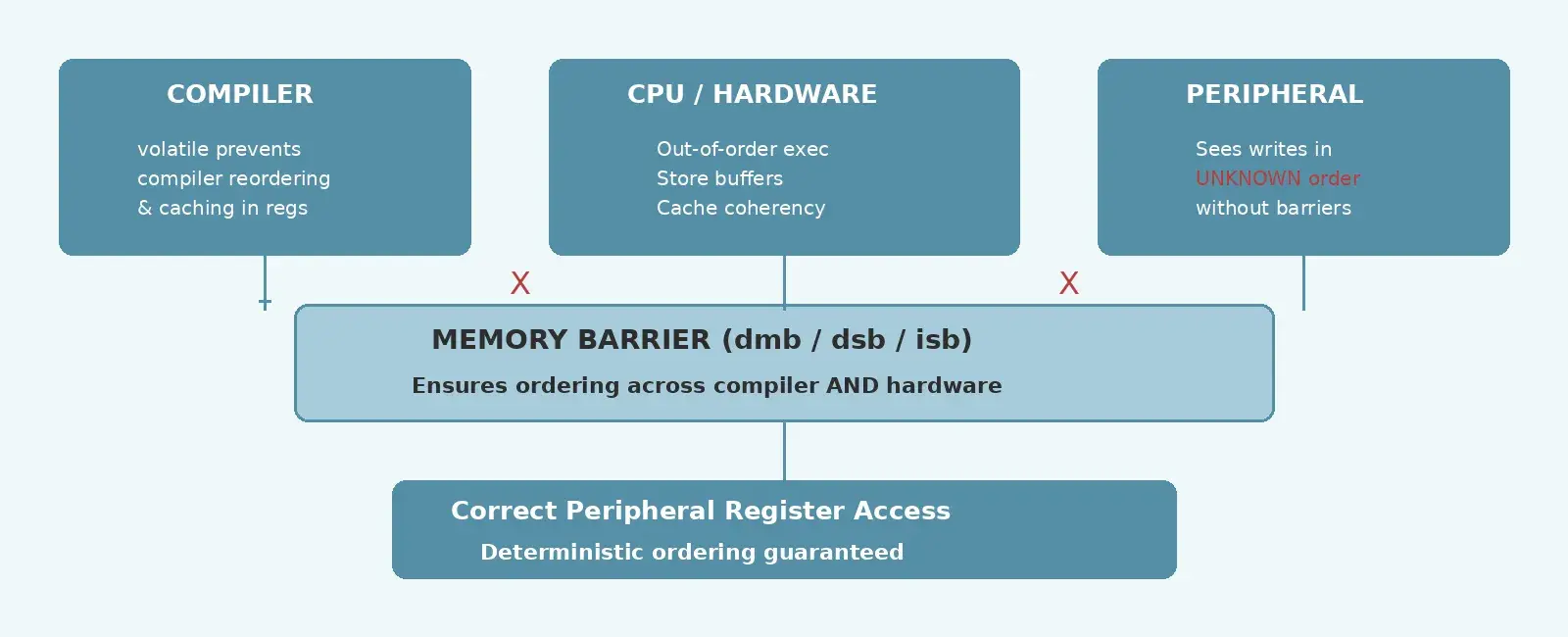
Table Of Contents
Every embedded developer learns about volatile early on — it tells the compiler not to optimize away reads or writes to a variable. But there is a persistent misconception that volatile guarantees memory ordering. It does not. On a modern out-of-order processor like the ARM Cortex-M, volatile is only half the story. The other half is memory barriers.
What Volatile Actually Does
volatile solves exactly two problems:
- Prevents the compiler from caching a value in a register — every read goes to memory.
- Prevents the compiler from reordering or eliminating accesses — the generated instructions appear in source order from the compiler’s perspective.
That second point is critical: the compiler respects volatile ordering only at the compiler level. Once the instructions are emitted, the CPU hardware is free to reorder them.
The scope of volatile can be visualized as a layer that only covers the compiler’s transformation:
+================================================================+|C SOURCE CODE || ||*DATA = value; *FLAG = 1; |+----------------------------------------------------------------+| v || volatile prevents compiler reordering || v |+================================================================+|COMPILER OUTPUT (ASM) || ||str r0, [DATA] ; str r1, [FLAG] |+----------------------------------------------------------------+| v || NO volatile protection! CPU can reorder || v |+================================================================+|HARDWARE EXECUTION || ||[FLAG] may reach peripheral BEFORE [DATA] |+================================================================+
The compiler faithfully emits DATA before FLAG. But between the compiler output and actual hardware execution, the CPU’s write buffer, store forwarding, and out-of-order execution engine can reorder the two stores. A peripheral monitoring both registers would see the writes arrive in the wrong order. This is precisely the gap dmb fills.
volatile uint32_t *FLAG = (volatile uint32_t *)0x40000000;volatile uint32_t *DATA = (volatile uint32_t *)0x40000004;void send(uint32_t value) {*DATA = value; // Compiler emits this first*FLAG = 1; // Compiler emits this second}
The compiler will generate the store to DATA before the store to FLAG. But if the CPU has a write buffer or out-of-order execution, the peripheral might see FLAG set before DATA is written. The ordering the compiler guaranteed is not the ordering the hardware executes.
The Three ARM Barriers
ARM Cortex-M provides three distinct memory barrier instructions:
| Barrier | Full Name | What It Does |
|---|---|---|
dmb | Data Memory Barrier | Ensures all explicit memory accesses before the dmb complete before any explicit memory accesses after it begin |
dsb | Data Synchronization Barrier | Ensures all explicit memory accesses and cache/TLB maintenance operations complete before any instruction after it executes |
isb | Instruction Synchronization Barrier | Flushes the processor pipeline so that all instructions after it are fetched fresh |
In embedded C, you typically access these via compiler intrinsics or CMSIS wrappers:
#include <cmsis_gcc.h> // or <cmsis_armcc.h>__DMB(); // Data Memory Barrier__DSB(); // Data Synchronization Barrier__ISB(); // Instruction Synchronization Barrier
When to Use Each Barrier
DMB — Peripheral Register Ordering
Use dmb when you need to ensure one peripheral write completes before another begins. The classic example is the “send” pattern above:
void send(uint32_t value) {*DATA = value;__DMB(); // Ensure DATA write completes before FLAG write*FLAG = 1;}
dmb is the lightest barrier — it only orders explicit memory accesses. It does not wait for cache maintenance or pipeline flushes.
DSB — Completion Guarantee
Use dsb when you need to know that a memory access has fully completed before proceeding. The most common case is waiting for a peripheral to finish a triggered operation:
// Trigger a DMA transferDMA1_Channel1->CCR |= DMA_CCR_EN;__DSB(); // Wait until the enable write is fully visible// Now it's safe to check status or trigger another operationwhile (!(DMA1->ISR & DMA_ISR_TCIF1)) { /* wait */ }
dsb is heavier than dmb — it waits for all memory accesses and cache/TLB operations to complete. Use it when the completion of a write matters, not just its ordering relative to other writes.
ISB — After System Configuration Changes
Use isb after modifying system configuration that affects instruction execution — for example, after changing the vector table offset, enabling/disabling interrupts globally, or modifying MPU regions:
// Relocate vector tableSCB->VTOR = new_vector_table_addr;__DSB(); // Ensure the write completes__ISB(); // Ensure subsequent instructions use the new vector table
Without the isb, the processor might still use stale instructions from the old context. The isb flushes the pipeline so all subsequent instructions are fetched with the new configuration.
A Practical Pattern: Semaphore in Multi-Core or DMA Context
Consider a shared flag between the CPU and a DMA controller:
+----------------------------------------------------------+|CPU Shared Memory ||+----------+ +------------------+ ||| | <------> | (flag, data) | ||+----------+ +--------+---------+ |+----------------------------------------------------------+| | || +------v------+ || | DMA | || | Controller | || +-------------+ |
The DMA writes a completion flag in shared memory. The CPU polls it:
volatile uint32_t *done_flag = (volatile uint32_t *)0x20001000;// Start DMA transfer...start_dma_transfer();// Poll for completionwhile (*done_flag == 0) {// Spin}__DMB(); // Ensure subsequent reads see the data the DMA wroteprocess_data();
Here, volatile ensures the compiler actually reads done_flag from memory each iteration. The __DMB() after the loop ensures that when the CPU reads process_data(), all the memory writes the DMA made are visible and ordered after the flag read.
Without the dmb, the CPU could speculatively read data from process_data() before the flag check completes, seeing stale data.
Common Mistake: Volatile as a Barrier
This code looks correct but is subtly broken:
// BROKEN: volatile does NOT prevent hardware reorderingvoid configure_timer(void) {TIM2->ARR = 999; // Auto-reload valueTIM2->PSC = 79; // PrescalerTIM2->CR1 |= TIM_CR1_CEN; // Enable timer}
The compiler will emit these in order, but the CPU might reorder the prescaler write after the enable. The timer starts with the old prescaler value. The fix:
// CORRECT: barrier between configuration and enablevoid configure_timer(void) {TIM2->ARR = 999;TIM2->PSC = 79;__DMB(); // Ensure all config writes completeTIM2->CR1 |= TIM_CR1_CEN; // Now safe to enable}
Barrier Cheat Sheet
| Scenario | Barrier Needed |
|---|---|
| Ordering peripheral register writes | __DMB() |
| Waiting for a write to complete | __DSB() |
| After changing VTOR / MPU / PRIMASK | __DSB() + __ISB() |
| After modifying control registers | __ISB() |
| Polling a DMA / shared memory flag | __DMB() after the poll |
| Context switch in RTOS | __DSB() + __ISB() |
Summary
volatile and memory barriers solve different problems. volatile prevents the compiler from optimizing away or reordering memory accesses. Memory barriers (dmb, dsb, isb) control the order in which those accesses are actually executed by the hardware.
The rule of thumb: if you are communicating with a peripheral or another bus master (DMA, second core), you need both volatile and the appropriate barrier. volatile alone is sufficient only when a single master (the CPU) reads a value that an ISR or hardware changes — and even then, only for the compiler. When hardware ordering matters, reach for the barrier.
Related Reading
- Understanding Volatile Keyword in Embedded C — the foundation that this post builds on
- DMA Programming in Embedded C for High-Throughput Data Transfer — where barriers are essential for correct DMA operation
- Lock-Free Ring Buffers for ISR-to-Task Communication — another concurrency pattern where ordering matters
Related Posts
DMA Programming in Embedded C for High-Throughput Data Transfer
June 12, 2026
3 min

Struct Packing and Serialization for Embedded Protocols
June 09, 2026
4 min
Compiler Attributes and Pragma Directives in Embedded C
June 04, 2026
5 min
Memory Alignment and Padding in Embedded C Demystified
June 02, 2026
4 min

Type Punning and Strict Aliasing in Embedded C
June 01, 2026
3 min
Quick Links
Legal Stuff