




Cortex-M Fault Handlers and Exception Handling in Embedded C
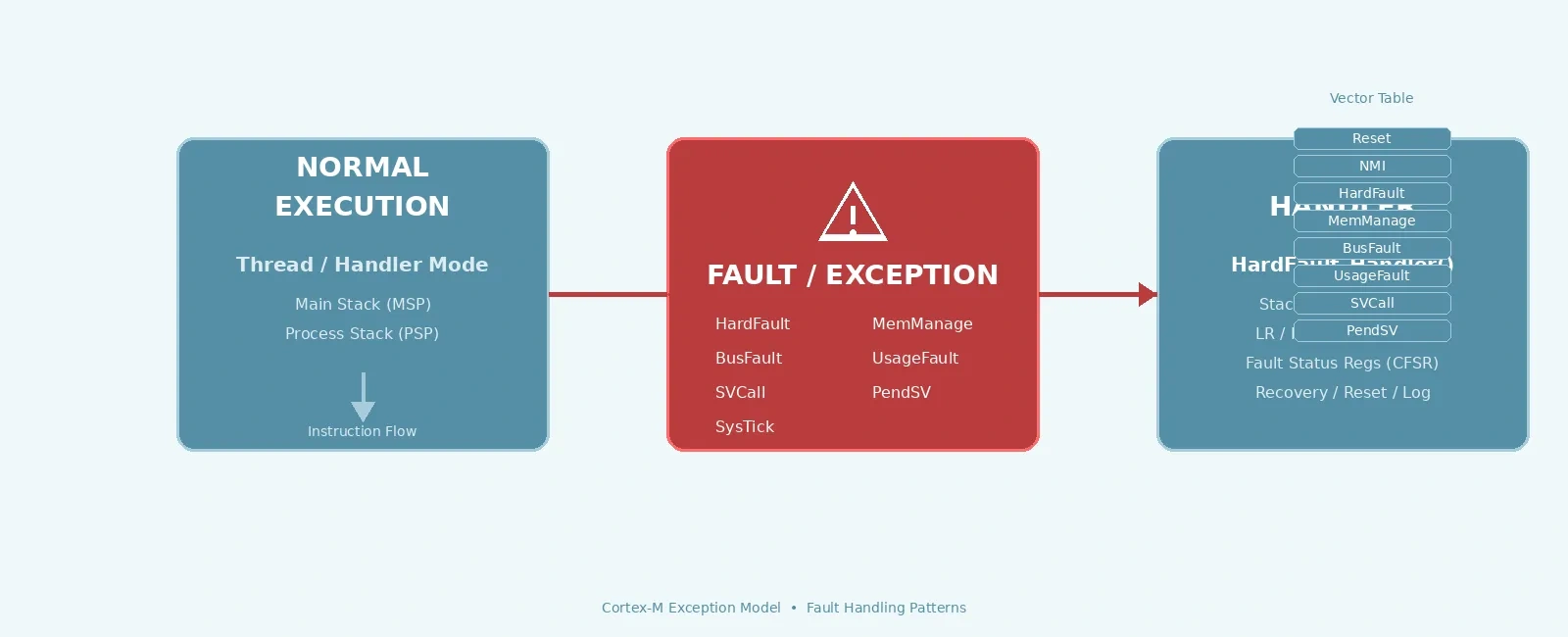
Table Of Contents
01
The Cortex-M Exception Model
02
Exception Stack Frame: What Hardware Saves
03
Fault Status Registers: The Debug Rosetta Stone
04
Exception Priority and Preemption
05
A Production-Ready HardFault Handler
06
Common Fault Scenarios and Root Causes
07
Debugging Workflow: From Crash to Cause
08
Preventing Faults: Design Practices
09
Summary
10
Related Reading
11
References
12
Frequently Asked Questions
Cortex-M fault handling is one of those topics that separates embedded engineers who ship reliable firmware from those who chase ghosts. When a HardFault hits in production, the difference between a two-minute debug session and a two-day mystery comes down to whether your fault handler captures the right context — and whether you know how to read it.
This article walks through the Cortex-M exception model, the anatomy of a fault stack frame, the key status registers that tell you what went wrong, and a practical fault handler template you can drop into your project today.
The Cortex-M Exception Model
Cortex-M processors use a unified exception model where everything — interrupts, faults, system calls, the SysTick timer — enters through the same hardware mechanism. The Nested Vectored Interrupt Controller (NVIC) manages prioritization, preemption, and tail-chaining automatically.
+--------------------------------------------------------------------------+| Cortex-M Exception Flow |+==========================================================================+| || [ NORMAL EXECUTION ] || Thread Mode (PSP) || Handler Mode (MSP) || Main Stack (MSP) || Process Stack (PSP) || || | || v || | || || [ FAULT / EXCEPTION OCCURS ] || HardFault | MemManage | BusFault | UsageFault || SVCall | PendSV | SysTick | External IRQ || || | || v || | || || [ VECTOR TABLE LOOKUP ] || VTOR -> Exception Number -> Handler Address || || | || v || | || || [ FAULT HANDLER EXECUTION ] || HardFault_Handler() / MemManage_Handler() || BusFault_Handler() / UsageFault_Handler() || || 1. Stack Frame Auto-Saved (xPSR, PC, LR, R0-R3, R12) || 2. LR = EXC_RETURN (0xFFFFFFF1/9/D) indicates || return stack (MSP/PSP) and mode (Thread/Handler) || 3. Read CFSR/HFSR/DFSR/AFSR for fault cause || 4. Read MMFAR/BFAR for faulting address || || | || v || | || || [ RECOVERY / ACTION ] || Fix cause -> Return (BX LR) || Log fault -> System reset (NVIC_SystemReset) || Enter safe mode / blink LED / watchdog || |+--------------------------------------------------------------------------+
The processor maintains two stack pointers: MSP (Main Stack Pointer) used in Handler mode and at reset, and PSP (Process Stack Pointer) typically used in Thread mode when an RTOS is present. On exception entry, hardware automatically pushes an 8-word stack frame onto the current stack.
Exception Stack Frame: What Hardware Saves
When any exception occurs, the processor pushes this frame without software intervention:
+--------------------------------------------------------------------+| Exception Stack Frame (Auto-Saved by Hardware) |+====================================================================+| || HIGH ADDR +--------+ xPSR <- Program Status Register || | | || +--------+ PC <- Program Counter (return address) || | | || +--------+ LR <- Link Register (EXC_RETURN code) || | | || +--------+ R12 <- R12 (scratch register) || | | || +--------+ R3 <- R3 || | | || +--------+ R2 <- R2 || | | || +--------+ R1 <- R1 || | | || LOW ADDR +--------+ R0 <- R0 (first argument) || || EXC_RETURN (LR) decoding: || 0xFFFFFFF1 = Return to Handler mode, MSP || 0xFFFFFFF9 = Return to Thread mode, MSP || 0xFFFFFFFD = Return to Thread mode, PSP || Bit[4]=1 -> PSP used, Bit[4]=0 -> MSP used |+--------------------------------------------------------------------+
The LR value on entry (EXC_RETURN) tells you exactly where the exception came from and which stack to use on return. Bit 4 is the key: 1 = PSP (Thread mode), 0 = MSP (Handler mode or Thread mode using MSP).
Fault Status Registers: The Debug Rosetta Stone
The Configurable Fault Status Register (CFSR) at 0xE000ED28 is actually three 8-bit registers packed together. Reading it as a 32-bit word gives you the complete picture.
+--------------------------------------------------------------------------+| Key Fault Status Registers (Cortex-M3/M4/M7) |+==========================================================================+| || CFSR (0xE000ED28) Configurable Fault Status Register UFSR[15:8] | BFS|| MMFSR (0xE000ED28) MemManage Fault Status IACCERR, DACCERR, || BFSR (0xE000ED29) BusFault Status IBUSERR, PRECISERR|| UFSR (0xE000ED2A) UsageFault Status UNDEFINSTR, INVSTA|| HFSR (0xE000ED2C) HardFault Status Register VECTTBL, FORCED, D|| DFSR (0xE000ED30) Debug Fault Status Register HALTED, BKPT, DWTT|| MMFAR (0xE000ED34) MemManage Fault Address Register Faulting data addr|| BFAR (0xE000ED38) BusFault Address Register Faulting bus addre|| AFSR (0xE000ED3C) Auxiliary Fault Status Register Vendor-specific (e|| |+--------------------------------------------------------------------------+
Key bits to check first:
| Register | Bit | Name | Meaning |
|---|---|---|---|
| MMFSR | 0 | IACCERR | Instruction access violation (MPU) |
| MMFSR | 1 | DACCERR | Data access violation (MPU) |
| MMFSR | 3 | MUNSTKERR | Stacking error on exception entry |
| MMFSR | 4 | MSTKERR | Unstacking error on exception return |
| MMFSR | 7 | MMARVALID | MMFAR holds valid fault address |
| BFSR | 0 | IBUSERR | Instruction bus error |
| BFSR | 1 | PRECISERR | Precise data bus error |
| BFSR | 2 | IMPRECISERR | Imprecise data bus error |
| BFSR | 3 | BUNSTKERR | Bus error on stacking |
| BFSR | 4 | BSTKERR | Bus error on unstacking |
| BFSR | 7 | BFARVALID | BFAR holds valid fault address |
| UFSR | 0 | UNDEFINSTR | Undefined instruction |
| UFSR | 1 | INVSTATE | Invalid EPSR state (e.g., Thumb bit clear) |
| UFSR | 2 | INVPC | Invalid PC load (EXC_RETURN corruption) |
| UFSR | 3 | NOCP | No coprocessor (FPU access when disabled) |
| UFSR | 8 | UNALIGNED | Unaligned access (when UNALIGN_TRP=1) |
| UFSR | 9 | DIVBYZERO | Integer division by zero |
| HFSR | 1 | VECTTBL | Vector table read fault |
| HFSR | 30 | FORCED | Fault escalated to HardFault |
| HFSR | 31 | DEBUGEVT | Debug event caused HardFault |
FORCED (HFSR bit 30) is the smoking gun: it means a configurable fault (MemManage/BusFault/UsageFault) occurred but its handler wasn’t enabled or couldn’t execute, so it escalated to HardFault.
Exception Priority and Preemption
Cortex-M uses lower numerical value = higher priority. Fixed system exceptions have negative priorities that cannot be changed:
+--------------------------------------------------------------------+| Exception Priority & Preemption (Lower Value = Higher Priority) |+====================================================================+| || Exception Priority Type Description ||--------------------------------------------------------------------|| Reset -3 (Fixed) Highest System reset || NMI -2 (Fixed) Highest Non-maskable interrupt || HardFault -1 (Fixed) Highest All escalated faults || MemManage 0-255 Config MPU violation || BusFault 0-255 Config Bus error || UsageFault 0-255 Config Undefined instr, div/0 || SVCall 0-255 Config Supervisor call (SVC) || PendSV 0-255 Config Pendable service call || SysTick 0-255 Config System tick timer || External IRQs 0-255 Config Peripheral interrupts || || Preemption: Higher priority (lower num) interrupts lower priority || Priority grouping: PRIGROUP splits priority into group/subpriority |+--------------------------------------------------------------------+
Practical tip: Set fault handlers (MemManage, BusFault, UsageFault) to priority 0 (highest configurable) so they preempt everything except NMI/HardFault. This ensures you catch the fault before it escalates.
// Enable fault handlers at highest configurable priorityNVIC_SetPriority(MemoryManagement_IRQn, 0);NVIC_SetPriority(BusFault_IRQn, 0);NVIC_SetPriority(UsageFault_IRQn, 0);// Enable the fault handlers in SCB->SHCSRSCB->SHCSR |= SCB_SHCSR_MEMFAULTENA_Msk |SCB_SHCSR_BUSFAULTENA_Msk |SCB_SHCSR_USGFAULTENA_Msk;
A Production-Ready HardFault Handler
Here’s a minimal, dependency-free handler that captures everything you need for post-mortem analysis:
#include <stdint.h>#include "stm32f4xx.h" // or your CMSIS header// Persistent fault record in a noinit section (survives reset)__attribute__((section(".noinit.fault_record")))typedef struct {uint32_t cfsr; // Configurable Fault Status Registeruint32_t hfsr; // HardFault Status Registeruint32_t dfsr; // Debug Fault Status Registeruint32_t afsr; // Auxiliary Fault Status Registeruint32_t mmfar; // MemManage Fault Address Registeruint32_t bfar; // BusFault Address Registeruint32_t stacked_r0;uint32_t stacked_r1;uint32_t stacked_r2;uint32_t stacked_r3;uint32_t stacked_r12;uint32_t stacked_lr;uint32_t stacked_pc;uint32_t stacked_xpsr;uint32_t exc_return; // LR value on entry (EXC_RETURN)} fault_record_t;fault_record_t fault_record;__attribute__((naked)) void HardFault_Handler(void) {__asm volatile ("TST LR, #4 \n" // Test bit 4 of EXC_RETURN"ITE EQ \n" // If bit 4 == 0 -> MSP, else PSP"MRSEQ R0, MSP \n" // R0 = MSP"MRSNE R0, PSP \n" // R0 = PSP"B fault_handler_c \n" // Branch to C handler (R0 = stack frame ptr));}void fault_handler_c(uint32_t *stack_frame) {// Capture fault status registers first (before they potentially change)fault_record.cfsr = SCB->CFSR;fault_record.hfsr = SCB->HFSR;fault_record.dfsr = SCB->DFSR;fault_record.afsr = SCB->AFSR;fault_record.mmfar = SCB->MMFAR;fault_record.bfar = SCB->BFAR;// Stack frame layout: R0, R1, R2, R3, R12, LR, PC, xPSRfault_record.stacked_r0 = stack_frame[0];fault_record.stacked_r1 = stack_frame[1];fault_record.stacked_r2 = stack_frame[2];fault_record.stacked_r3 = stack_frame[3];fault_record.stacked_r12 = stack_frame[4];fault_record.stacked_lr = stack_frame[5];fault_record.stacked_pc = stack_frame[6];fault_record.stacked_xpsr = stack_frame[7];// EXC_RETURN was in LR on entry (passed via naked asm)// We can't easily retrieve it here without more asm, but PC/LR tell the story// Force a breakpoint if debugger attached__BKPT(0);// In production: log to flash, blink error code, or reset// NVIC_SystemReset();}
Key design choices:
__attribute__((naked))— no prologue/epilogue, we control the stack.noinitsection — survives soft reset for post-mortem debugging- Capture registers before any function calls that might clobber them
__BKPT(0)halts the debugger if attached; remove or guard for production
Common Fault Scenarios and Root Causes
| Symptom | Likely CFSR Bit | Typical Cause |
|---|---|---|
| HardFault on startup | VECTTBL (HFSR) | Vector table offset (VTOR) not set, or table in invalid memory |
| HardFault after enabling FPU | NOCP (UFSR) | CP10/CP11 not enabled in CPACR before FPU use |
| HardFault in ISR | FORCED (HFSR) + any CFSR bit | Lower-priority fault escalated (handler disabled or priority too low) |
Crash on printf/malloc | IMPRECISERR (BFSR) | Heap/stack collision, or accessing freed memory |
| Crash on unaligned struct access | UNALIGNED (UFSR) | Packed struct dereference on Cortex-M0/M3 (M4/M7 handle it unless UNALIGN_TRP=1) |
| Crash on division | DIVBYZERO (UFSR) | Integer divide by zero — check divisor |
| Crash on function pointer call | INVPC (UFSR) | Corrupted function pointer, bad EXC_RETURN |
| Crash after context switch | MSTKERR/MUNSTKERR (MMFSR) | Stack overflow, PSP/MSP misconfigured |
Debugging Workflow: From Crash to Cause
- Check HFSR first — if
FORCEDis set, look at CFSR for the original fault - Read CFSR — decode MMFSR/BFSR/UFSR to classify the fault
- If MMARVALID/BFARVALID set — read MMFAR/BFAR for the exact faulting address
- Examine stacked PC — this is the instruction after the faulting one (usually)
- Check stacked LR (EXC_RETURN) — tells you mode and stack used
- Map PC to source — use
addr2line -e firmware.elf <PC>or your IDE’s call stack - Inspect the faulting instruction — disassembly at PC-2/PC-4 reveals the operation
# Example: decode fault address from .elfarm-none-eabi-addr2line -e build/firmware.elf 0x0800423C# Output: src/tasks/comm_task.c:142
Preventing Faults: Design Practices
| Practice | Prevents |
|---|---|
| Enable all fault handlers at priority 0 | Silent escalation to HardFault |
| Use MPU for stack guards & null pointer detection | MemManage on stack overflow / NULL deref |
Initialize VTOR early in Reset_Handler | VECTTBL HardFault |
Enable FPU in SystemInit before any FP math | NOCP UsageFault |
| Validate all pointers before dereference | BusFault, MemManage |
Use static_assert for struct alignment | UNALIGNED UsageFault |
Guard division with if (divisor != 0) | DIVBYZERO UsageFault |
| Reserve RAM for fault record (.noinit) | Post-mortem analysis after reset |
Summary
Cortex-M fault handling isn’t black magic — it’s a deterministic hardware mechanism that tells you exactly what went wrong, provided you:
- Enable the configurable fault handlers (MemManage, BusFault, UsageFault) so faults don’t silently escalate
- Capture the stack frame and status registers before any C code runs
- Read CFSR/HFSR/MMFAR/BFAR systematically to classify the fault
- Preserve the fault record in non-volatile or
.noinitRAM for post-reset analysis
The naked assembly shim + C handler pattern shown here adds ~20 bytes of flash and gives you a fighting chance when the inevitable HardFault appears in the field.
Related Reading
- /memory-protection-and-mpu — Configuring the MPU for stack guards and memory regions
- /interrupt-handling-and-isrs — NVIC priority, preemption, and ISR best practices
- /arm-cortex-m-mpu-configuration-and-usage — Deep dive on MPU region setup
References
- ARM, Cortex-M3/M4/M7 Devices Generic User Guide, ARM DUI 0553A (2017) — Exception model, fault status registers, stack frame format.
- ARM, ARMv7-M Architecture Reference Manual, ARM DDI 0403E — Complete register definitions for CFSR, HFSR, MMFAR, BFAR, SHCSR.
- Joseph Yiu, The Definitive Guide to ARM Cortex-M3 and Cortex-M4 Processors, 3rd ed., Newnes (2013) — Chapter 12 (Fault Handling), Chapter 11 (Exceptions).
- STMicroelectronics, Programming Manual PM0214: STM32 Cortex-M4/M7/M33 MCUs — SCB register map, FPU enable sequence, VTOR configuration.
- Chris White, Cortex-M Hard Fault Debugging, Interrupt Blog (2019) — Practical handler templates and debug workflows.
- FreeRTOS, FreeRTOS Cortex-M Port Guide — PSP/MSP usage in Thread/Handler mode, context switching stack frames.
Frequently Asked Questions
What is the difference between HardFault and other fault types on Cortex-M?
HardFault is the catch-all exception with fixed priority -1 that handles all faults when their specific handlers (MemManage, BusFault, UsageFault) are disabled or when a fault occurs inside another fault handler. MemManage, BusFault, and UsageFault are configurable-priority exceptions that handle specific fault classes when enabled.
How do I decode the EXC_RETURN value in LR to know which stack was used?
Check LR bit[4]: if 1, the exception return uses the Process Stack Pointer (PSP); if 0, it uses the Main Stack Pointer (MSP). Common values: 0xFFFFFFF1 (return to Handler mode, MSP), 0xFFFFFFF9 (return to Thread mode, MSP), 0xFFFFFFFD (return to Thread mode, PSP).
Which registers should I read first when debugging a HardFault?
Read CFSR (0xE000ED28) to identify the fault type (MMFSR/BFSR/UFSR), then HFSR (0xE000ED2C) for HardFault-specific flags (FORCED, VECTTBL). If MMARVALID/BFARVALID bits are set, read MMFAR (0xE000ED34) or BFAR (0xE000ED38) for the faulting address.
Can I use printf or semihosting inside a fault handler?
Avoid printf/semihosting in fault handlers — they may require a working stack, heap, or debugger connection that the fault itself has corrupted. Use minimal register dumps via ITM/SWO, blink an LED pattern, or write to a reserved RAM buffer for post-mortem analysis.
Why does my HardFault handler never get called — the system just resets?
If the HardFault handler itself faults (e.g., stack overflow in the handler, or accessing invalid memory while debugging the fault), the processor escalates to a lockup state and typically triggers a system reset. Ensure your fault handler uses minimal stack, no function calls, and only safe register access.
Related Posts
Volatile vs Memory Barriers — When Volatile Isn't Enough
June 20, 2026
5 min
Bit-Banding in Embedded C — Atomic GPIO Manipulation Without Locks
June 19, 2026
3 min

Memory Protection Unit in Embedded Systems
May 20, 2026
4 min
Linker Scripts and Memory Layout in Embedded C: A Practical Guide
July 02, 2026
2 min

Understanding const and volatile Pointer Types in Embedded C
June 29, 2026
3 min
Quick Links
Legal Stuff